
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 산업공학
- 유전알고리즘
- Sarsa
- 코딩스타일
- multi task learning
- genetic algorithm
- q learning
- 확률공리
- 스네이크케이스
- off-policy
- 케밥케이스
- 헝가리안노테이션
- 강화학습
- 카멜케이스
- routing problem
- 연합학습
- Traveling salesman problem
- on-policy
- 몬테카를로 학습
- 그리드월드
- 파스칼케이스
- 배반사건
- Docker Image
- Federated learning
- mmoe
- 딥러닝
- 도커 컨테이너
- 큐러닝
- Metaheuristic
- 도커 개념
- Today
- Total
SU Library
[멀티테스크 러닝]Multi task learning with Multi-Gate Mixture-of-Experts 모델 개념 정리 및 구현 본문
[멀티테스크 러닝]Multi task learning with Multi-Gate Mixture-of-Experts 모델 개념 정리 및 구현
S U 2024. 6. 18. 09:12MMoE(Multi-gate Mixture-of-Experts)는 멀티태스크 학습(Multi-task Learning)을 위한 모델로, 여러 개의 전문가(Experts) 네트워크와 각각의 태스크(Task)마다 개별적으로 학습되는 게이트(Gate) 네트워크를 포함합니다. 이는 다양한 태스크 간의 상호작용을 캐치하고 이를 학습하도록 설계되었습니다.
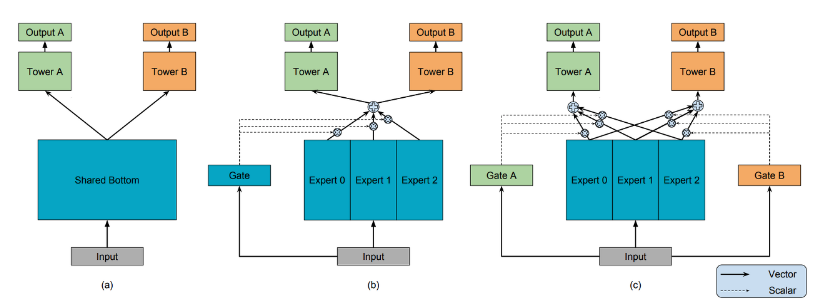
그림에서 보듯 크게 Expert , Gate로 구성되어있고 이 모듈들을 활용하여 Shared-Bottom mul-task DNN 구조를 갖습니다.
각각의 Experts는 일반적으로 feed-forward로 구성되어있고, 입력 데이터의 특징을 학습합니다. 또한, 각 태스크마다 별도의 Gate 네트워크가 존재합니다. Gate는 Experts를 통과한 값을 중합하여 최종 출력을 생성하고 softmax함수를 바탕으로 Experts의 가중치를 계산합니다. 이는 3명의 experts가 있다고 가정하면 1번 task는에 대한 출력값은 1번 expert를 50% 믿고 2번 expert를 30% 믿고 3번 expert를 20% 믿은 결정을 내리는 것입니다. 이 과정을 수식으로 표현하면,
$$y_k= h^k(f^k(x))$$
$$\mathrm{where, } f^k(x) = \sum_{i=1}^{n}g^k(x)_if_i(x)$$
입니다. $f_i$는 i번째 expert의 결과를 나타내고, $g$는 experts의 결과를 앙상블 하기위한 역할입니다. 그러나 본 논문에서는 이를 selective하게 expert를 선택한 후 앙상블을 취합니다. 이는 학습과 추론의 관점에서 앙상블보다 더 빠른 속도로 동작할 수 있다는 이점이 있습니다. 여기서 $k$는 테스크의 개수입니다. 아래는 여러개의 feedforward를 진행하는 것으로 멀티 테스크를 구현한 간단한 MMOE코드입니다.
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class Expert(nn.Module):
def __init__(self, input_size, hidden_size):
super(Expert, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
return x
class Gate(nn.Module):
def __init__(self, input_size, num_experts):
super(Gate, self).__init__()
self.gate = nn.Linear(input_size, num_experts)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
gate_weights = self.gate(x)
gate_weights = self.softmax(gate_weights)
return gate_weights
class MMoE(nn.Module):
def __init__(self, input_size, hidden_size, num_experts, num_tasks):
super(MMoE, self).__init__()
self.num_experts = num_experts
self.num_tasks = num_tasks
# Experts
self.experts = nn.ModuleList([Expert(input_size, hidden_size) for _ in range(num_experts)])
# Gates for each task
self.gates = nn.ModuleList([Gate(input_size, num_experts) for _ in range(num_tasks)])
# Task-specific output layers
self.task_layers = nn.ModuleList([nn.Linear(hidden_size, 1) for _ in range(num_tasks)])
def forward(self, x):
expert_outputs = torch.stack([expert(x) for expert in self.experts], dim=1)
outputs = []
for i in range(self.num_tasks):
gate_weights = self.gates[i](x)
gate_outputs = torch.sum(gate_weights.unsqueeze(2) * expert_outputs, dim=1)
task_output = self.task_layers[i](gate_outputs)
outputs.append(task_output)
return outputs
# 모델 하이퍼파라미터 설정
input_size = 10
hidden_size = 16
num_experts = 4
num_tasks = 2
# 데이터 생성 (예제용으로 랜덤 데이터 사용)
np.random.seed(42)
X = np.random.rand(1000, input_size)
y1 = np.random.rand(1000, 1)
y2 = np.random.rand(1000, 1)
X = torch.tensor(X, dtype=torch.float32)
y1 = torch.tensor(y1, dtype=torch.float32)
y2 = torch.tensor(y2, dtype=torch.float32)
# 모델 초기화
model = MMoE(input_size, hidden_size, num_experts, num_tasks)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 학습
epochs = 100
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X)
loss1 = criterion(outputs[0], y1)
loss2 = criterion(outputs[1], y2)
loss = loss1 + loss2
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 예측
model.eval()
with torch.no_grad():
predictions = model(X)
print(predictions)
'인공지능 > Deep learning' 카테고리의 다른 글
| [연합학습] Federated Learning의 개념과 간단예제 (0) | 2024.12.03 |
|---|
